2. Modellierung des sprachlichen Variantenreichtums
Verschiedene Akteure beeinflussen den Verlauf eines Zusammenschlussversuchs und bilden untereinander ein komplexes Beziehungsnetzwerk. So kann beispielsweise im Fall einer feindlichen Übernahme der Aufsichtsrats des Zielunternehmens seinen Aktionären empfehlen, keine Aktien zu verkaufen und dadurch die Übernahme gefährden. Die Haltung der Aktionäre, aber auch die des Kartellamts, kann einen Zusammenschluss zum Scheitern bringen. Um diese Prozesse zu modellieren, muss das Korpus im Hinblick auf die Akteure, ihre Entscheidungen und Meinungen untersucht werden. Zur Extraktion von Ereignissen besteht bereits eine große Bandbreite an Fachliteratur, die grob in maschinelle, musterbasierte und hybride Vorgehensweisen eingeteilt werden kann (Hogenboom et al. 2011). Auch zur automatischen Bestimmung des faktischen Status von Ereignissen sowie zur automatischen Analyse von Wirtschaftsnachrichten hat es bereits einige Ansätze gegeben (z. B. Saurí / Pustejovsky 2012; Nassirtoussi 2014). Im vorliegenden Beitrag soll am Beispiel von Aktionärsabstimmungen gezeigt werden, wie semi-automatisch ermittelte morpho-syntaktische Muster den Kontext des Zusammenschlusses semantisch mittels lokaler Grammatiken (Gross 1997) modellieren können. Die mithilfe der Muster gewonnenen Informationen können z. B. für eine semantische Suchmaschine genutzt werden, um Fragen der Art „Wie oft waren Aktionäre für das Scheitern einer Fusion in den letzten 2 Jahren verantwortlich?“ oder „Wer trug zum Scheitern der Übernahme von Tele Columbus durch Kabel Deutschland bei?“ beantworten zu können.
2.1. Datenbasis
Um die von deutschsprachigen Wirtschaftsnachrichten erwähnten Einflüsse der Aktionäre auf einen Zusammenschluss (und umgekehrt) zu erfassen, wurden mithilfe des COSMAS-Tools (vgl. Institut für Deutsche Sprache) 6784 Sätze zusammengestellt, die jeweils die Schlüsselwörter („Übernahme“ ODER „Fusion“) sowie „Aktionäre“ enthalten. Die über das COSMAS-Tool verfügbaren Korpora bestehen hauptsächlich aus den Archiven regionaler und überregionaler deutschsprachiger Zeitungen. Mit der Keyword-Auswahl sollen die wichtigsten Ereignisse identifiziert werden, die während eines Zusammenschlusses im Zusammenhang mit den Aktionären stehen. Folgende Tabelle zeigt einen Auszug aus den manuell erstellten relevanten Themen sowie die dazugehörigen sprachlichen Muster:

Tab. 1: Konfidenzmaß ausgewählter Keywords bzgl. bestimmter Phasen
2.2. Korpusverarbeitungssystem und Modellierungswerkzeug
Da Medienberichte in Wirtschaftsnachrichten wiederkehrende Sprachmuster für die Ankündigung gescheiterter und erfolgter Zusammenschlüsse benutzen, ist der Ansatz der lokalen Grammatiken für diese Aufgabe vielversprechend (Gross 1997). Lokale Grammatiken erlauben es, morpho-syntaktische sowie semantische Eigenschaften der Sprache zu berücksichtigen. Zur Implementierung verwende ich das Korpusverarbeitungssystem Unitex, das an der Université Marne-la-Vallée entwickelt wurde.
Am Centrum für Informations- und Sprachverarbeitung wurde in München ein sehr umfangreiches deutschsprachiges Lexikon aufgebaut, das zahlreiche syntaktische und semantische Informationen mit einschließt und sich dadurch erheblich von vergleichbaren Systemen absetzt (Guenthner / Maier 1994). Neben der Verfügbarkeit dieses Lexikons bietet Unitex den Vorteil, dass der Benutzer selbst Regeln zur Erkennung von Named Entities schreiben und dabei eine Vielzahl an morphologischen und syntaktischen sowie semantischen Einschränkungen einbauen kann. Für die vorliegende Studie wurde z. B. ein Lexikon mit Organisationsnamen mit über 335000 Einträgen eingesetzt (Mallchok 2004).
2.3. Lokale Grammatiken zur Differenzierung bestimmter Phasen
Für die Auswahl geeigneter und besonders charakteristischer Schlüsselpassagen werden zunächst die einschlägigen verbalen Wendungen (z. B. „zustimmen“, „grünes Licht geben“) im Textkorpus ermittelt. Da die isolierte Erkennung der Prädikate allein oft nicht ausreicht, um eine Aussage korrekt zu extrahieren, muss der jeweilige Kontext berücksichtigt werden. Es geht also darum, die syntaktische Distributionsklasse des Prädikats (Anzahl und Form der Komplemente) zu ermitteln (vgl. Nagel 2005: 16). Das Verb „genehmigen“ erfordert im untersuchten Bereich beispielsweise ein Subjekt, das die Aktionäre beschreibt, und ein Objekt, den Zusammenschluss. Sie werden anschließend in Unitex-Graphen eingearbeitet, die auf neuen Korpora den Status eines Unternehmenszusammenschlusses bestimmen können. Die Graphen können durch die Einbindung von Lexika und Kontextmodellierung zudem relevante Entitäten wie z. B. den Unternehmensnamen erkennen. Lokale Grammatiken eignen sich in besonderem Maße für das in diesem Beitrag behandelte Thema, da sie die syntaktische Struktur des Satzes berücksichtigen und somit der Akteur und im Zusammenhang dazu seine Handlungen oder Meinungen extrahiert werden können. Kleinere Entitäten können einzeln erkannt und in den Kontext eines größeren Graphs eingebettet werden. Folgender (etwas vereinfachter) Graph erkennt z. B. das Abstimmungsergebnis:
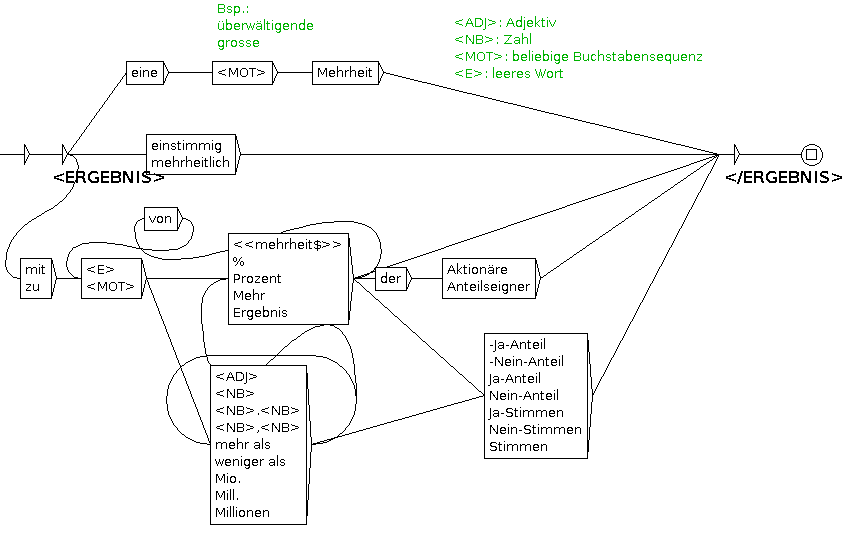
Abb. 1: Graph zur Erkennung des Abstimmungsergebnisses
Die erkannten Textstellen werden mit XML-Tags versehen und im Textformat abgespeichert, sodass sie leicht visualisiert und weiterverarbeitet werden können.
Beispiele für mit diesem Graphen erkannte Textstellen sind:

Abb. 2: Auszug aus der Konkordanz der erkannten Textstellen zum Abstimmungsergebnis
Folgende Beispiele zeigen einen Auszug aus der Konkordanz des Graphen zur Erkennung des Abstimmungsergebnisses von Aktionären:

Abb. 3: Auszug aus der Konkordanz der erkannten Textstellen zur Aktionärsabstimmung
Durch Ersetzen der Prädikate können Synonyme gefunden werden, wie z. B. „erlauben“, oder aber auch Prädikate wie „vereiteln“ und „verhindern“, die die Ablehnung des Zusammenschlusses ausdrücken. Hinsichtlich der Argumentstruktur unterscheiden sich die Prädikate nicht, sie müssen jedoch aufgrund ihrer Bedeutung verschieden annotiert werden. Ebenso können durch Ersetzen des Subjekts die Entscheidungen anderer Akteure, beispielsweise des Kartellamts, erkannt werden.
Oft ist auch nur von dem Plan einer Aktionärsabstimmung die Rede. Dieser wird häufig in Form von Modalverbkonstruktionen zum Ausdruck gebracht:

Abb. 4: Auszug aus der Konkordanz der erkannten Textstellen zu einer geplanten Aktionärsabstimmung
Die Extraktion der analysierten Prädikat-Argument-Strukturen mithilfe von lokalen Grammatiken ermöglicht die Kategorisierung eines Ereignisses, im vorliegenden Fall der Aktionärsabstimmung, das für die Einschätzung des Status eines Zusammenschlusses von zentraler Bedeutung ist.
2.4. Evaluation
Tabelle 2 zeigt die Ergebnisse einer Evaluation bezüglich der erfolgten Zustimmung der Aktionäre zu einem Zusammenschluss. Sie wurde auf einem mithilfe der COSMAS-Datenbank erstellten Testkorpus mit 623 Sätzen (Keywords: („Fusion“ ODER „Übernahme“) sowie „Aktionäre“) durchgeführt. Hierbei wurden sowohl die Erkennung der Relation als auch der daran beteiligten Entitäten wie z. B. Unternehmensnamen, Zeit- und Ortsangaben berücksichtigt.
| Zustimmung der Aktionäre zu einem Zusammenschluss | Entitäten | |
| Precision | 100/101=99,0% | 117/120=97,5% |
| Recall | 66/100=66,0% | 120/197=60,9% |
| F-Score | 79,2% | 75,0% |
Tab. 2: Ergebnisse der Evaluation bezüglich der erfolgten Zustimmung der Aktionäre zu einem Zusammenschluss
2.5. Fazit und Ausblick
Im vorliegenden Beitrag wird gezeigt, wie wiederkehrende sprachliche Muster dazu genutzt werden können, die Rolle von Aktionären bei einem Unternehmenszusammenschluss am Beispiel von Aktionärsabstimmungen zu modellieren. Mithilfe von lokalen Grammatiken kann der Ausgang der Abstimmungen automatisch extrahiert werden. Wichtige Entitäten wie Zeit- und Ortsangaben, Akteure und Organisationsnamen werden ebenfalls erkannt. Die so strukturierten Informationen können anschließend in eine semantische Suchmaschine eingebettet werden. Mit dieser Methode und durch Erweiterung der vorhandenen Muster kann in den nächsten Schritten ein System zur Erkennung der relevanten Phasen eines Zusammenschlusses sowie das Zusammenwirken der unterschiedlichen Akteure erstellt werden. Nach der Fertigstellung des Systems sollen bezüglich neuer Zeitungsnachrichten Aussagen zum derzeitigen Stand eines Zusammenschlusses getroffen werden können. In einem nächsten Schritt wäre auch eine Analyse hinsichtlich sprachlicher Indikatoren interessant, die nicht unmittelbar an ökonomische Schritte geknüpft ist: Inwiefern kündigen Passagen wie „droht zu scheitern“ tatsächlich das Scheitern des Prozesses an? Darüber hinaus könnte auch die sprachliche Modellierung von Gerüchten („Der Konsumgüterhersteller Henkel ist Kreisen zufolge Favorit im Rennen um den Haarpflegespezialisten Wella“, vgl. Focus 25.05.2015) mit lokalen Grammatiken implementiert werden, um die Grenze zwischen klaren Fakten und unsicheren Aussagen in Zeitungsnachrichten zu markieren. Die Methode ist in thematischer Hinsicht nicht auf ein bestimmtes Textkorpus beschränkt, die Graphen müssen jedoch bei Wechsel der Textdomäne angepasst werden.