Biber Hanno / Breiteneder, Evelyn / Dobrovol’skij, Dmitrij (2002): ''Corpus-based study of collocations in the AAC'', in: Braasch, Anna / Povlsen, Claus (eds.): Proceedings of the Tenth EURALEX International Congress, Vol. 1. Center for Sprogtknologi, Kopenhagen.
Björkelund, Anders / Farkas, Richárd (2012): ''Data-driven Multilingual Coreference Resolution using Resolver Stacking'', in: Joint Conference on EMNLP and CoNLL - Shared Task , Jeju Island, Korea. ACL 49–55.
Dobrovol’skij, Dmitrij (2014): ''Russkie obrašcenija v parallel’nych korpusach'', in: Die Welt der Slaven , LIX, 1: 1-21.
Dolan, William B. / Brockett, Chris (2005): ''Automatically constructing a corpus of sentential paraphrases'', in: Third International Workshop on Paraphrasing (IWP2005). Asia Federation of Natural Language Processing.
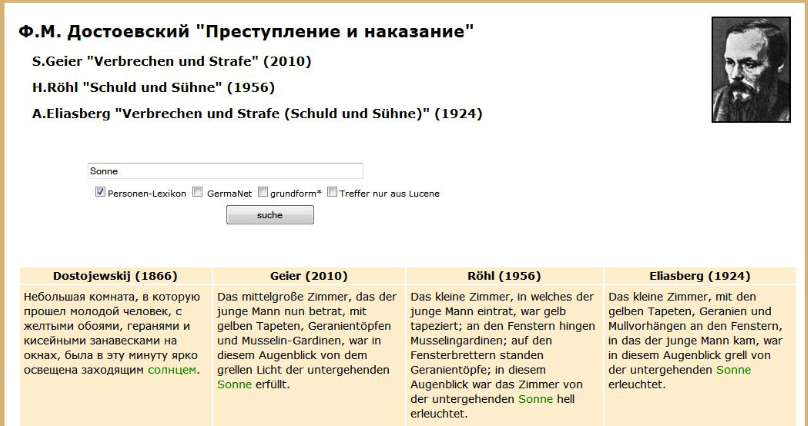
Dostojewskij, Fjodor M. (1924): Verbrechen und Strafe (Übersetzung von Alexander Eliasberg) . Potsdam: Gustav Kiepenheuer Verlag.
Dostojewskij, Fjodor M. ( 1956): Schuld und Sühne (Übersetzung von Hermann Röhl). Berlin: Aufbau Verlag.
Dostojewskij, Fjodor M. (2010): Verbrechen und Strafe (Übersetzung von Swetlana Geier). Frankfurt am Mian: Fischer Taschenbuch Verlag.
Faruqui, Manaal / Padó, Sebastian (2010): ''Training and evaluating a German named entity recognizer with semantic generalization'', in: Proceedings of KONVENS 2010 , Saarbrücken, Germany.
Finkel, Jenny Rose / Grenager, Trond / Manning, Christopher (2005): ''Incorporating non-local information into information extraction systems by gibbs sampling'', in: Proceedings of the 43rd Annual Meeting on ACL , ACL ’05, Stroudsburg, PA, USA. ACL 363–370.
Ganitkevitch, Juri / Van Durme, Benjamin / Callison-Burch, Chris (2013): ''PPDB: The paraphrase database'', in: Proceedings of NAACL-HLT , Atlanta, Georgia, June. ACL.
Grishina, Yulia / Stede, Manfred (2015): ''Knowledgelean projection of coreference chains across languages'', in: Proceedings of the Eight Workshop on Building and Using Comparable Corpora , Beijing, China. ACL.
Kobdani, Hamidreza / Schütze, Hinrich / Schiehlen, Michael / Kamp, Hans (2011): ''Bootstrapping coreference resolution using word associations'', in: Proceedings of the 49th Annual Meeting of the ACL: Human Language Technologies , Portland, Oregon, USA, June. ACL 783–792.
Nivre, Joakim / Hall, Johan / Nilsson, Jens / Chanev, Atanas / Eryigit, Gülsen / Kübler, Sandra / Marinov, Svetoslav / Marsi, Erwin (2007): ''MaltParser: A Language-Independent System for Data-Driven Dependency Parsing'', in: Natural Language Engineering 13, 2: 95–135.
Och, Franz Josef / Ney, Hermann (2003): ''A systematic comparison of various statistical alignment models'', Computational Linguistics 29, 1: 19–51.
Postolache, Oana / Cristea, Dan / Orasan, Constantin (2006): ''Transferring coreference chains through word alignment'', in: Proceedings of the 5th International Conference on Language Resources and Evaluation.
Pradhan, Sameer / Ramshaw, Lance / Marcus, Mitchell / Palmer, Martha / Weischedel, Ralph / Xue, Nianwen (2011): ''CoNLL-2011 Shared Task: Modeling Unrestricted Coreference in OntoNotes'', in: Proceedings of the CoNLL 2011: Shared Task , Portland, Oregon, USA. ACL.
Pradhan, Sameer / Moschitti, Alessandro / Xue, Nianwen / Uryupina, Olga / Zhang, Yuchen (2012): ''CoNLL-2012 Shared Task: Modeling Multilingual Unrestricted Coreference in OntoNotes'', in: Joint Conference on EMNLP and CoNLL - Shared Task , Jeju Island, Korea. ACL.
Rafferty, Anna / Manning, Christopher D. (2008): ''Parsing three German treebanks: Lexicalized and unlexicalized baselines'', in: Proceedings of the Workshop on Parsing German, Columbus, Ohio, June. ACL 40–46.
Rahman, Altaf / Ng, Vincent (2012): ''Translation-based projection for multilingual coreference resolution'', in: Proceedings of NACL:HLT 2012 , Montréal. ACL.
Recasens, Marta / Màrquez, Lluís / Sapena, Emili / Martí, M. Antònia / Taulé, Mariona / Hoste, Véronique / Poesio, Massimo / Versley, Yannick (2010): ''SemEval-2010 task 1: Coreference resolution in multiple languages'', in: Proceedings of SemEval 2010 , Uppsala, Sweden. ACL.
Schmid, Helmut (1994): ''Probabilistic part-of-speech tagging using decision trees'', in: International Conference on New Methods in Language Processing , Manchester, UK.
Schmid, Helmut ( 1995): ''Improvements in Part-of-Speech Tagging with an Application to German'', in: Workshop of the Special Interest Group for Linguistic Data and Corpus-based Approaches to Natural Language Processing (EACL 1995 SIGDAT-Workshop) 47–50.
Sharoff, Serge / Nivre, Joakim (2011): ''The proper place of men and machines in language technology. Processing russian without any linguistic knowledge'', in: Proceedings of the International Conference on Computational Linguistics and Artificial Intelligence Dialog 2011, Moscow.
Souza, Jose Guilherme Camargo / Orasan, Constantin (2011): ''Can projected chains in parallel corpora help coreference resolution?'', in: Hendrickx, Iris / Devi, Sobha Lalitha / Branco, Antonio / Mitkov, Ruslan (eds.): Anaphora Processing and Applications (= Lecture Notes in Computer Science 7099). Berlin / Heidelberg: Springer.
Zhekova, Desislava (2013) Towards Multilingual Coreference Resolution . Ph.D. thesis, University of Bremen.
Zhekova, Desislava / Zangenfeind, Robert / Mikhaylova, Alena / Nikolaienko, Tetiana (2014): ''Alignment of Multiple Translations for Linguistic Analysis'', in: Proceedings of the The 3rd Annual International Conference on Language, Literature and Linguistics (L3) , Bangkok, Thailand.
Zhekova, Desislava / Zangenfeind, Robert / Mikhaylova, Alena / Nikolaienko, Tetiana (2015): ''Sentence-Alignment and Application of Russian-German Multi-Target Parallel Corpora for Linguistic Analysis and Literary Studies'', in: Portela, Manuel (ed.): Digital Literary Studies 3 (to appear).